
Software Engineering is the new Manufacturing Engineering
LLMs are regression-to-the-mean machines--they pull junior developers up, and drag senior developers down. Taming them requires trading the romance of 'code as craft' for the physics of manufacturing.

Why does vibe-coding seem so mesmerizing and even magical at first--yet just weeks into a project, predictably fail to deliver the low-risk, dependable software a business actually needs?
I believe LLMs have pushed a large portion of the software engineering discipline from the domain of "code as craft" into the domain of manufacturing engineering--in other words: making stuff, but with statistical control.
This is transforming what we think of as "coding" from a handmade trade (like a ceramic potter) to an industrial process. It's akin to engineering a rocket part with a high-speed CNC machine: the tool is incredibly powerful, but without strict gauges to catch when a cut drifts out of spec, it will quickly ruin the entire part.
LLMs' probabilistic machinery has made the discipline of Statistical Process Control relevant to all software engineers who use AI for coding:
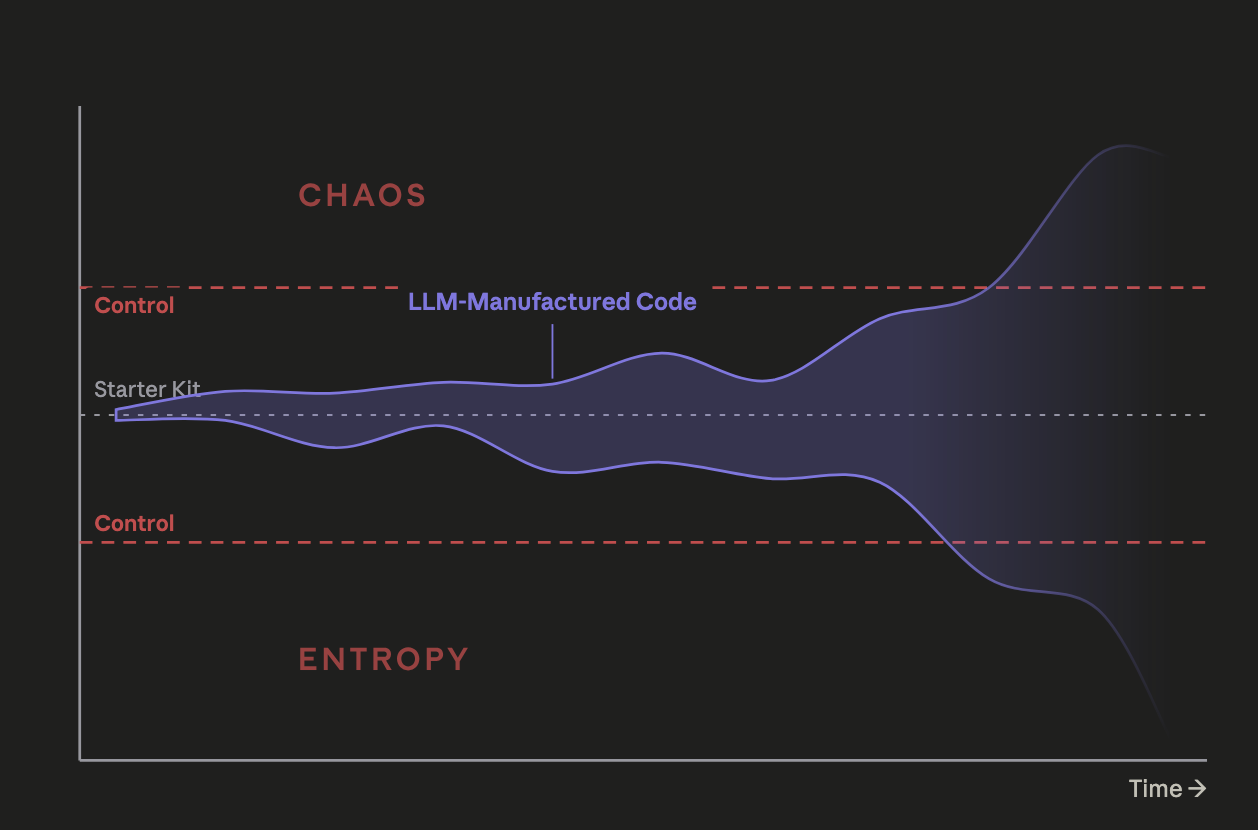
An LLM is, at its core, a statistical machine. But it is a rose with thorns: the very ability that enables it to create magic also enables it to create chaos (the service is down!), and also entropy ("tech debt"). The chaos and entropy can grow so large that vibe coders who once felt euphoric soon feel frustrated and even discouraged as the LLM won't make the code do what they want any more.
By "statistical machine", I mean that an LLM is a regression machine: in everything it does, it regresses to the mean over the inputs that it's trained on. If you take no code at all as a starting point, and tell it what to do, it will produce code! Mediocre code, but probably functioning code. If you take well-engineered code as a starting point, and tell it what to do, it will produce, over time, mediocre code.
Regression to the mean feels very different, as an experience, depending on your perspective and where you begin--whether you begin from above or below the line of "LLM averageness."
If you are kind of new to producing working software--if your ability to code, alone, would produce below-average code (for example, if someone had asked you, "Do you know how to code?" a few years ago and your answer had been, "No") then the experience of an LLM in the domain of software engineering will be magical. You will produce things the likes of which you never thought possible. You will write an app that serves the exact itch you had always wanted to scratch, and it will be glorious. If you are a non-engineering CEO, it will appear at first that software engineers are wasteful, lavish, slow-moving resources.
If you are skilled at producing working software--if your ability to code is above the mean (for example, you are a software engineer of several years) then the experience of an LLM in the domain of software engineering will be frustrating. Sometimes it will pleasantly surprise you. Often it will make poor decisions--sometimes remarkably stupid ones. As someone whose job it is to reduce risk to the business in the long run (i.e. an engineer), exclusive use of an LLM to produce code looks foolhardy.
I've chosen coding as one skill. But feel free to expand this general principle--choose any skill domain that LLMs are currently disrupting--generating art, producing film, storytelling, copywriting, email correspondence, etc.--and apply the same rules. If you are below the mean, it will feel like magic. Above the mean, frustration. A regression-to-the-mean-machine pulls you up if you're below, and down if you're above.
The New Discipline: Statistical Software Manufacturing
So where is this going? I think what we're seeing is the emergence of a new discipline, which I'll call Statistical Software Manufacturing (SSM). The motivation behind it is to take advantage of the insanely powerful abilities of LLMs, without their adverse effects--like modern manufacturing uses Statistical Process Control to reject widgets below a certain quality threshold. We aren't there yet, but I'm seeing glimmers of this new direction opening up.
In SSM, as in manufacturing, we can introduce Control Limit Violations (CLVs). An example of a CLV in manufacturing would be "the target diameter is >10mm." In SSM, the equivalent might be measuring the Functional Core / Imperative Shell metric in typescript: by traversing the Abstract Syntax Tree, a CLI tool like fcis (linked above) can deterministically flag when an LLM interleaves database calls or other I/O with pure math.
Then, if an LLM generates a new feature or fixes a bug, we don't accept its output until we measure it against FC/IS scores. And if it's measured to introduce a lower FC/IS score than we can tolerate, just like manufacturing engineering, we "rework" (explain to the LLM how it failed, and feed it back through), or "scrap" (discard, and start fresh).
Software engineers are already familiar with several other Control Limit Violation classes:
- unit tests
- linting
- type checking
In each case, these deterministic measurements help trip a CLV, sending non-conformant code back to be re-worked or scrapped.
I believe we're just at the beginning--we need many more control limits. For example: Can we write CLVs that strictly forbid the src/ directory from importing the infrastructure/ directory (GritQL would be great for this)? Can we deterministically measure if an LLM is hard-coding global or module-level instantiations instead of using Dependency Injection?
Each time we can create a good, deterministic metric, we create an invariant that prevents the regression-to-the-mean-machine from undoing one of our existing better-than-average results.
And I think what would make an invariant "good" would be its ability to defeat Goodhart's law ("When a measure becomes a target, it ceases to be a good measure.") If we gave an LLM a single metric to optimize, it would inevitably game it. But in SSM, we would use competing constraints acting as floors, not high scores. We wouldn't give the AI a target to full-on maximize--we'd force its output through a structural gauntlet so it can't cheat:
- The Type Checker: Does it compile?
- The Linter: Is the cyclomatic complexity low?
- The FC/IS analyzer: Is the I/O separated from the math?
- The copy/paste detector (jscpd): Has anything been duplicated?
- The Test Suite: Does the behavior match the business requirement?
- ... and others, as the SSM discipline grows ...
Because this gauntlet is deterministic and repeatable, every new control we add allows us to enforce tighter tolerances on the AI's output. We are leaving behind the magical worldview—where token streams just hopefully work—and moving toward Statistical Process Control that simply rejects raw token results that fall out of spec.
I think this is how we'll eventually cure the vibe-coding hangover. We'll create CLVs that limit a codebase from drifting outside of the control lines. By completing the transition from "code as craft" to something like Statistical Software Manufacturing, we'll harness the powerful output of the regression machine without running afoul of the chaos it's likely to produce when left to drift.
And for the business, the win is clear: SSM will drive down the cost of software development while keeping catastrophic risk firmly below the tolerance levels of customers, investors, and regulators.
Special thanks to Caleb B. for thoughtful conversation that inspired this post.